This site contains datasets, applications, tools and other resources publicly available. Other resources can possibly be found on the archived site of the Knowledge Engineering Group.
Datasets
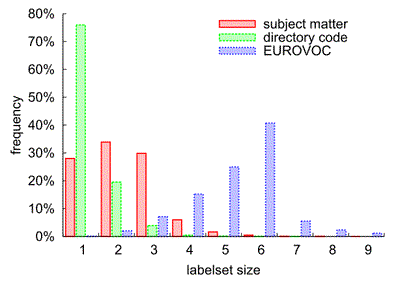
EUR-Lex text collection
The EUR-Lex text collection provides a large multlabel classification benchmark with up to 4000 different classes.
Medical Concept Embeddings: code and data
Concept vector representations learned from a large labeled background corpus. These were used for computing the semantic similarity between terms from the medical domain.
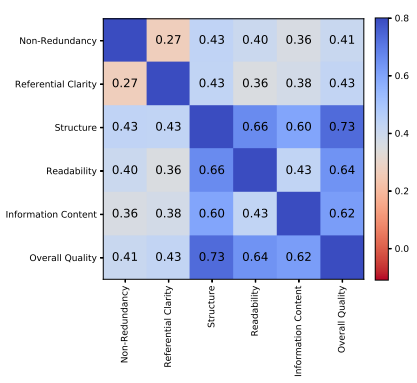
DIP-SumEval: A Data Set of Human Summary Evaluations
The first data set of judgements of automatic multi-document summarization systems on large variety of quality dimensions. Contains over 400 automatically generated summaries for 49 topics of an data set for multi-document summarization, 1274 judgements according to 11 text and summary quality criteria on a Likert-scale (1 to 5) performed by 26 trained annotators, and 43218 pairwise judgements according to 6 criteria performed by 64 crowd-workers.
Software and Source Code

BOOMER: an algorithm for learning gradient boosted multi-label classification rules
Efficient and scalable scikit-learn implementation for learning gradient boosted multi-label classification rules.
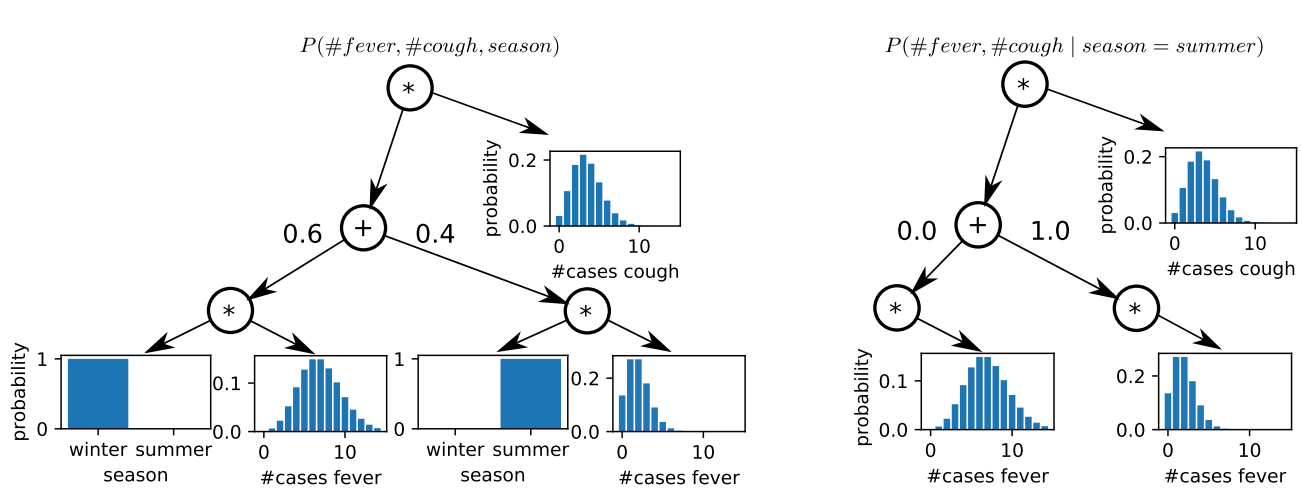
NSS: Framework for Non-Specific Syndromic Surveillance
Software framework including state-of-the-art approaches, statistical baselines and an advanced approach based on sum-product networks.
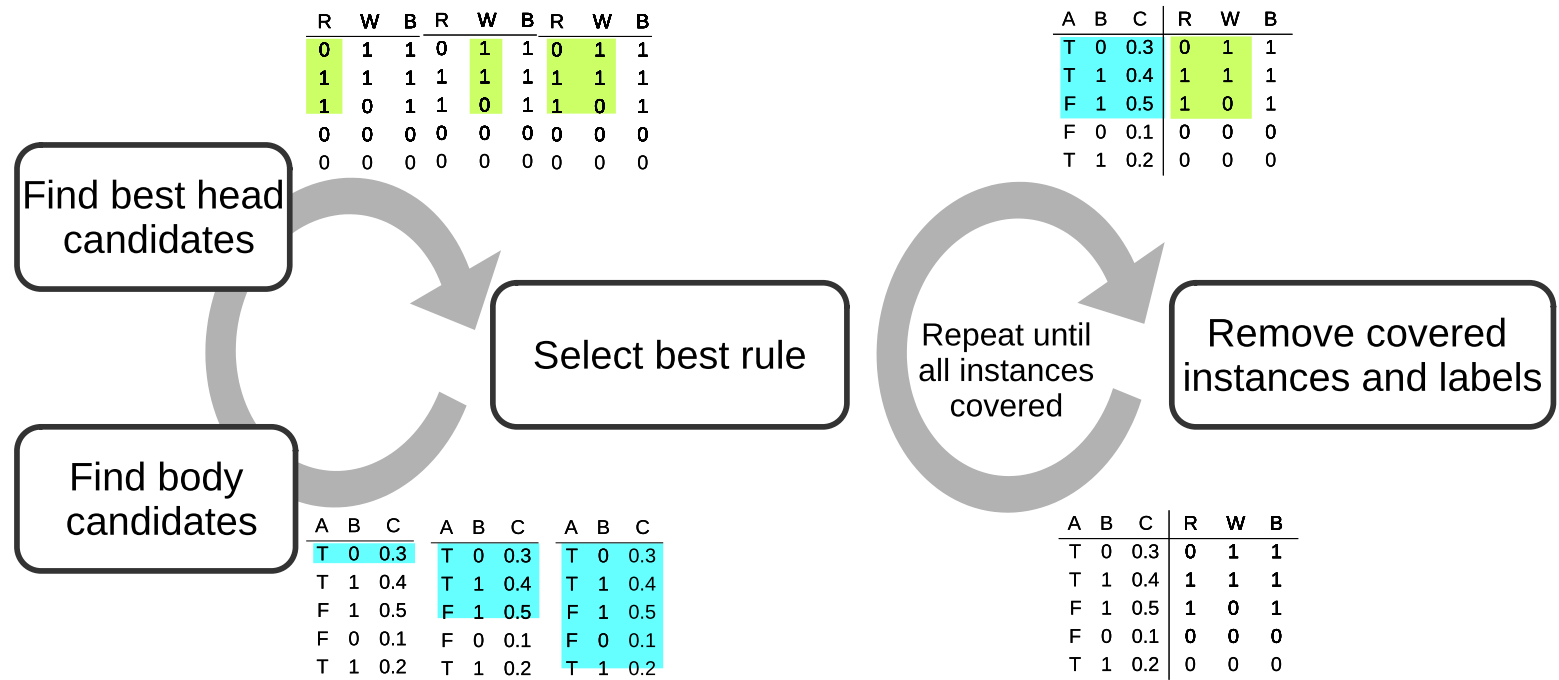
SeCo for learning multi-label rules
Separate-and-conquer rule-learning framework for learning multi-label head rules.

Extreme Dynamic Classifier Chains
Dynamic classifier chains version of extreme gradient boosted trees (XGBoost) for multi-label classification
MLC2seq
Dynamic classifier chains version of recurrent neural networks for predicting one by one, in a sequence, the labels in multi-label classification tasks.
Graded Multilabel Classification, code and new data sets
The code and data used for our paper about pairwise graded multilabel classification. In this setting, a label is not only present or absent, but can have several grades, e.g. stars.
TUD poker framework
Framework for testing end developing computer bots, such as counter-factual regret minimization or neural network based bots.

P³oodle: a personalizing, privacy-protecting browser add-on for searching the web
Personalized web site ranking with different techniques from IR on the own computer.
All-in-Text
Learn continuous vector representations jointly for words, documents, and labels. Use corpora with labelled documents and use also descriptions of labels. This enables also to do zero-shot learning, i.e., to predict labels for which no documents were observed during training.
Archive
Classification GUI
A graphical user interface that allows to intuitively assign concepts from an ontology to a set of documents in order to quickly and easily develop a (multilabel) classification dataset.
Perceptrovement
A highly modular framework for the efficient Perceptron algorithm containing a great collection of effective extensions